How to adjust the likelihood approximation parameter
Introduction
The likelihood associated to the following noise model
cannot be written simply without resortint to a hierarchical model.
The MixingModelsLikelihood class implements the approximation proposed in Section II of Palud et al. [2023].
The approximation combines a Gaussian approximation:
and a lognormal approximation
where \(m_{m,n\ell}\), \(s_{m,n\ell}^2\), \(m_{a,n\ell}\) and \(s_{a,n\ell}^2\) are obtained with moment matching. The combination \(\widetilde{\pi}\) is defined as a weighted geometric mean of the two likelihood functions \(\pi^{(a)}\) and \(\pi^{(m)}\) associated to these two approximations:
The weight \(\lambda(\theta_n, a_\ell) \in [0, 1]\) of the multiplicative approximation depends on a parameter \(a_\ell\) that pinpoints special positions:
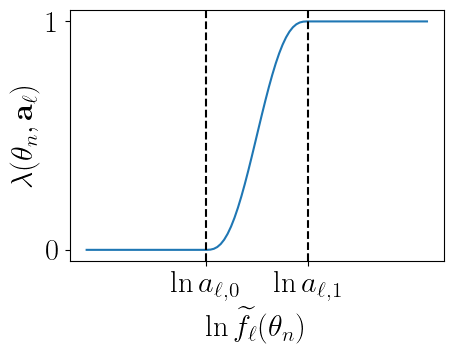
In this document, we explain how to adjust the parameter to obtain a good approximation of the true likelihood. The used approach is presented in the Appendix A of Palud et al. [2023].
Perform optimization
For real observations, it is very simple to tune the parameters \(a_\ell\), as one simply needs to run:
python beetroots/approx_optim/nn_bo_real_data.py input_nn_bo_fast.yaml ./data/ngc7023 ./data/models .
where
beetroots/approx_optim/nn_bo_real_data.pyis the python file to executeinput_nn_bo_fast.yamlis the name of the yaml file that defines the run to be executed./data/ngc7023is the path of the folder that contains the noise standard deviations./data/modelsis the path of the folder that contains the already saved models (e.g., polynomial approximations, neural networks, etc.).is the path of the result folder (to be created), where the run results are to be saved
with the .yaml file:
list_lines: # List[str]: names of the lines for which the parameters are to be adjusted
- "co_v0_j11__v0_j10"
- "co_v0_j12__v0_j11"
- "co_v0_j13__v0_j12"
- "co_v0_j15__v0_j14"
- "co_v0_j16__v0_j15"
- "co_v0_j17__v0_j16"
- "co_v0_j18__v0_j17"
- "co_v0_j19__v0_j18"
#
- "h2_v0_j2__v0_j0"
- "h2_v0_j3__v0_j1"
- "h2_v0_j4__v0_j2"
- "h2_v0_j5__v0_j3"
- "h2_v0_j6__v0_j4"
- "h2_v0_j7__v0_j5"
#
- "chp_j1__j0"
- "chp_j2__j1"
- "chp_j3__j2"
# data
filename_int: "Nebula_NGC_7023_Int.pkl" # map of observations
filename_err: "Nebula_NGC_7023_Err.pkl" # map of additive standard deviation
sigma_m_float_linscale: 1.3 # multiplicative noise standard deviation in linear scale (sigma_m = log(sigma_m_float_linscale)). Constant over the full map.
# parameters to run the optimization
simu_init:
name: "bo_nn_ngc7023"
D: 5
D_no_kappa: 4
K: 20
log10_f_grid_size: 100
N_samples_y: 10_000 # 200_000 # 250_000
max_workers: 3
# parameters to set up the optimization
main_params:
dict_forward_model:
forward_model_name: "meudon_pdr_model_dense"
force_use_cpu: true
fixed_params: # must contain all the params in list_names of the SImulation object. Values are in linear scale.
kappa: null
P: null
radm: null
Avmax: null
angle: 60.0
is_log_scale_params: # defines the scale to work with for each param (either log or lin)
kappa: True
P: True
radm: True
Avmax: True
angle: False
#
lower_bounds_lin:
- 1.0e-1 # kappa
- 1.0e+5 # Pth
- 1.0e+0 # G0
- 1.0e+0 # AVtot
- 0.0 # angle
upper_bounds_lin:
- 1.0e+1 # kappa
- 1.0e+9 # Pth
- 1.0e+5 # G0
- 4.0e+1 # AVtot
- 60.0 # angle
n_iter: 40
and the python code:
import os
import sys
from typing import List
import numpy as np
import yaml
from beetroots.approx_optim.nn_bo import ApproxParamsOptimNNBO
from beetroots.simulations.astro.observation.abstract_real_data import (
SimulationRealData,
)
class ReadDataRealData(SimulationRealData):
r"""implements an ``__init__`` method for :class:`.SimulationRealData`"""
def __init__(self, list_lines: List[str]) -> None:
"""
Parameters
----------
list_lines : List[str]
observables for which the likelihood approximation parameters are to be adjusted
"""
self.list_lines_fit = list_lines
if __name__ == "__main__":
yaml_file, path_data, path_models, path_outputs = ApproxParamsOptimNNBO.parse_args()
# step 1: read ``.yaml`` input file
with open(os.path.abspath(f"{path_data}/{yaml_file}")) as f:
params = yaml.safe_load(f)
# step 2: read the additive noise standard deviations for the specified
# lines
data_reader = ReadDataRealData(params["list_lines"])
(_, _, sigma_a, _, _, _, _) = data_reader.setup_observation(
data_int_path=f"{path_data}/{params['filename_int']}",
data_err_path=f"{path_data}/{params['filename_err']}",
save_obs=False,
)
# step 3: run the Bayesian optimization
approx_optim = ApproxParamsOptimNNBO(
list_lines=params["list_lines"],
sigma_a=sigma_a,
sigma_m=np.log(params["sigma_m_float_linscale"]),
**params["simu_init"],
path_outputs=path_outputs,
path_models=path_models,
)
approx_optim.main(**params["main_params"])
Results
Evolution of the Gaussian process mean during the optimization process:
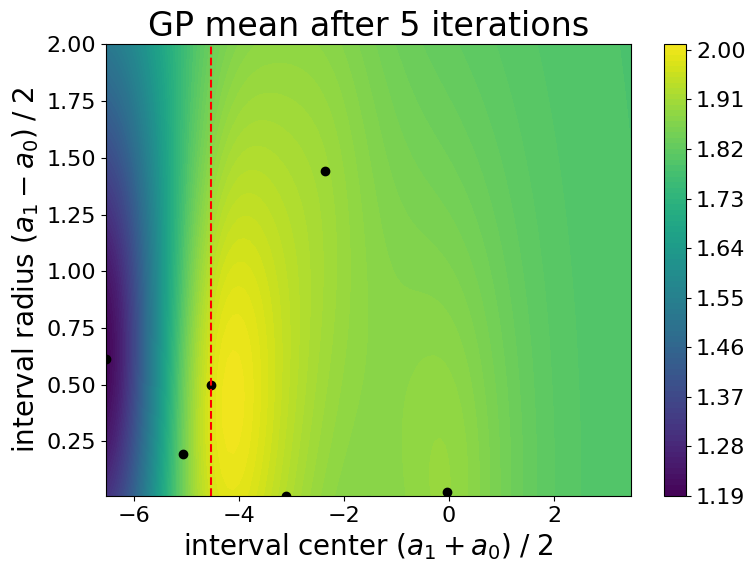
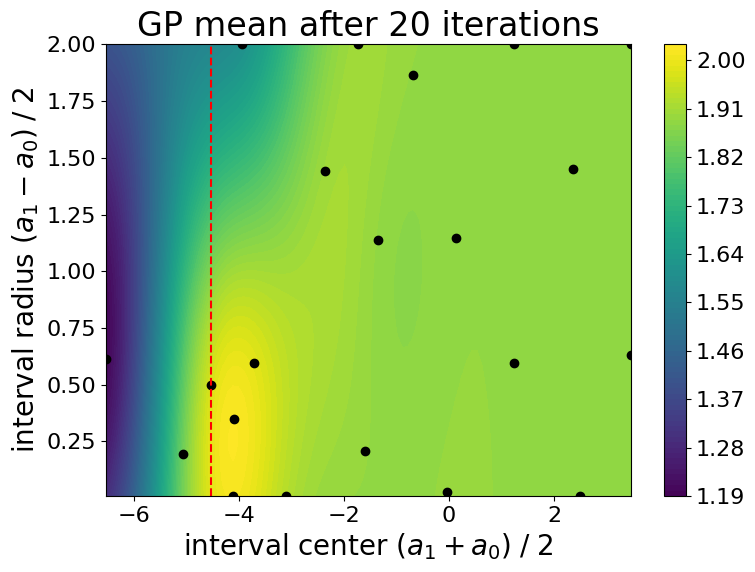
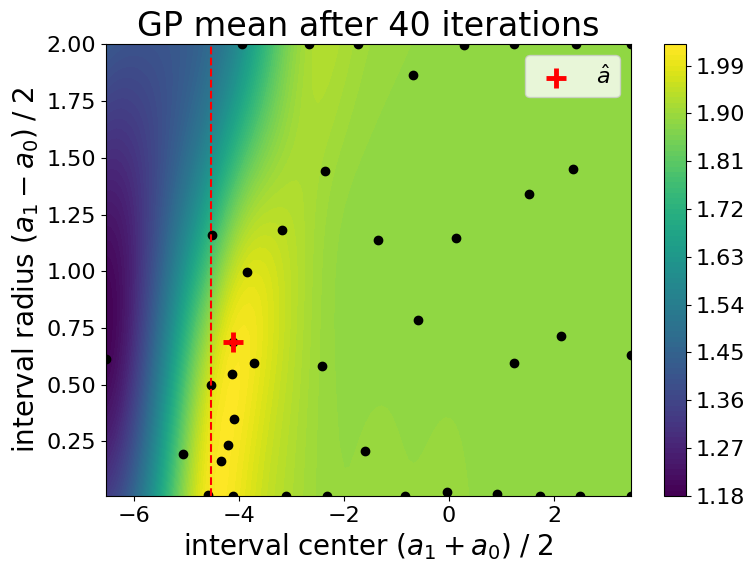
Evolution of the Gaussian process standard deviation (i.e., uncertianty on the cost function) during the optimization process:
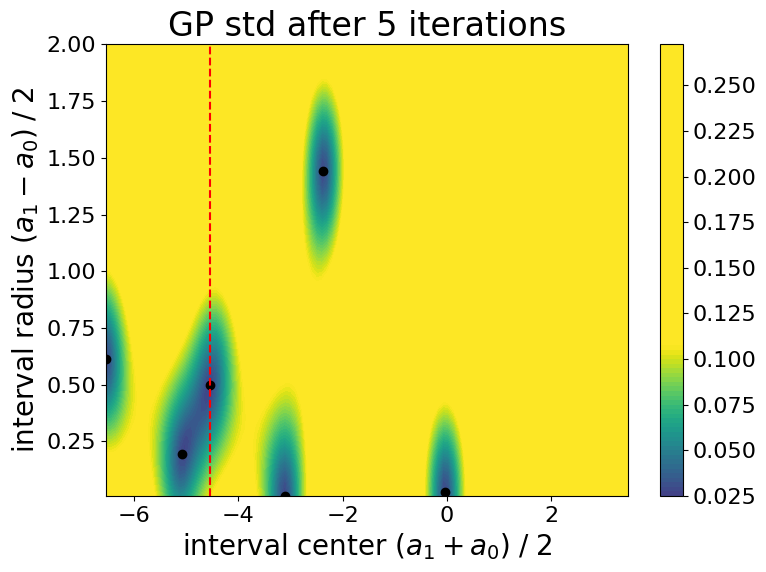
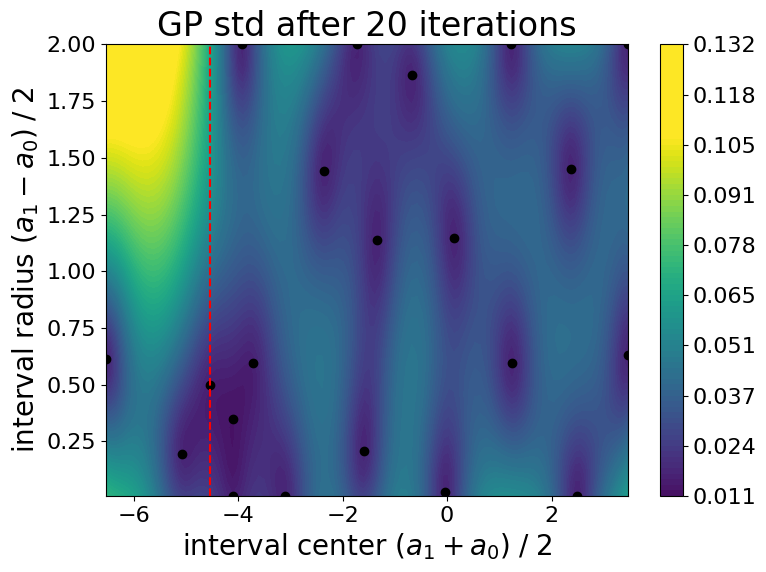
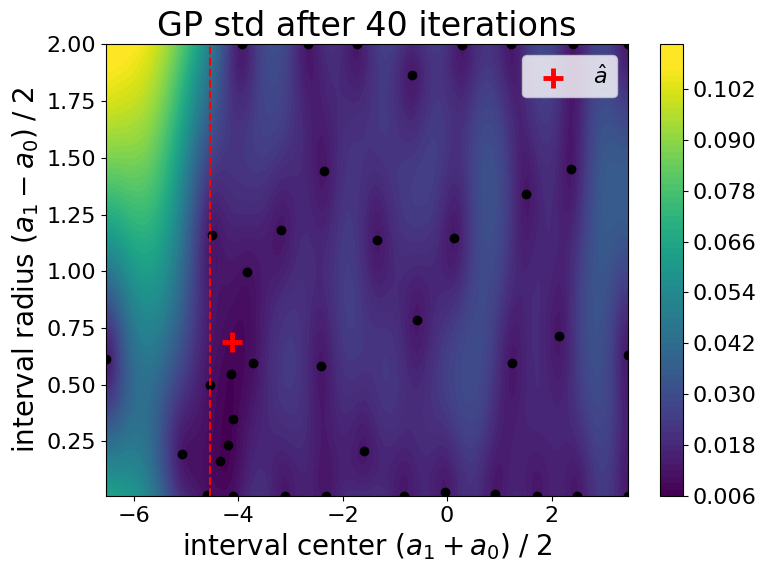
Final weight function \(\lambda\) :
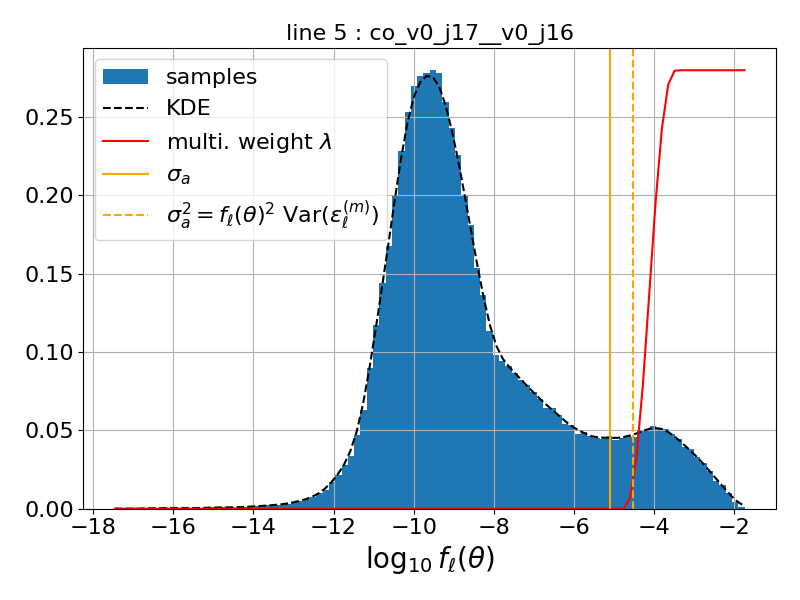
Among other intermediate outputs, the command above will create a best_params.csv file that is needed for any inference based on the MixingModelsLikelihood likelihood.